Das Canonical Tag – Beispiele & Tipps 2026

©Shutterstock/Roman023_photography
Im technischen SEO gibt es ein häufig diskutiertes und oft missverstandenes Thema: der richtige Einsatz des Canonical Tags. Um euch ein fundiertes und umfassendes Verständnis von dem berüchtigten HTML Tag zu geben, haben wir an dieser Stelle die wichtigsten Fakten, Tipps und Beispiele zusammengetragen.
Funktion des Canonical Tags
Zunächst möchten wir die Frage beantworten, was das Meta Tag “Canonical” überhaupt bedeutet und welchen Nutzen es für Webseitenbetreiber hat.
Mithilfe einer Canonical Angabe bei HTML-Dokumenten Head-Bereich des Quellcodes gibt man Google einen Hinweis darauf, ob es sich bei dem jeweiligen Inhalt um Unique Content, also einzigartigen Inhalt, oder ob es sich um Duplicate Content handelt. Denn nach wie vor sind doppelte Inhalte ein Negativsignal für Google und Co. Was zählt, sind einzigartige Inhalte, die dem Nutzer einen Mehrwert bieten und dessen Suchintention befriedigen. Mit einem Verweis auf die kanonische URL (auch Standardressource genannt), zeigt ihr der Suchmaschine, welche Seite die Originalversion enthält und am Ende auch ranken soll. So verhindert ihr bei Seiten mit demselben oder gleichem Inhalt, dass eure Seite Minuspunkte im Ranking wegen nicht gekennzeichneter Duplikate erntet.
Und so sieht eine kanonische URL bei HTML-Dokumenten aus:
<link rel="canonical" href="https://www.onlinesolutionsgroup.de/">Bei anderen Dateitypen wie z.B. PDFs muss das Canonical Tag im HTTP-Header einer Seite mit rel=”canonical” gesetzt sein
<http://www.domain/inhalt.html>; rel="canonical"Einsatz des Tags bei Duplicate Content
Doppelte Inhalte zu vermeiden, stellt eine der höchsten Prioritäten in der Suchmaschinenoptimierung dar. Wer gut ranken möchte, sollte einen Großteil seiner Ressourcen in einzigartige Texte und selbst erstellte Medien investieren. Eine eindeutige Prozentzahl, wie viel Inhalt einer Seite mit einer anderen Seite gespiegelt werden darf, gibt es nicht. SEO Experten empfehlen jedoch so wenig wie möglich zu duplizieren. Ist es trotzdem mal passiert, kann man mithilfe verschiedener Tools Duplikate finden. Ein besonders häufig genutztes Programm dafür nennt sich Copyscape. Hier kann man entweder einen ganzen Text oder eine URL einfügen und das Tool zeigt einem mögliche Duplikate im World Wide Web.
Duplicate Content kann in den verschiedensten Fällen auftreten und lässt sich nicht in einem Satz beschreiben. Umso differenzierter muss man auch den Einsatz des Canonicals bei doppelten Inhalten betrachten. Häufig ist der Einsatz eines Canonical Tags zwar möglich, jedoch nicht empfehlenswert. Daher haben wir die möglichen Anwendungsfälle für euch zusammengetragen sowie Best Practises und Empfehlungen aus unserer SEO Erfahrung ergänzt.

Fall 1: Duplicate Content durch die URL
Doppelte Inhalte entstehen häufig in Folge mehrerer URLs für den gleichen Inhalt. Solche URLs kommen meist unbeabsichtigt zustande. Oft wissen die Webmaster gar nichts über dieses verhältnismäßig große SEO Problem.
Startseiten-Datei: Von index.html bis index.php
Ein Paradebeispiel für Duplicate Content aufgrund der URL ist die Benennung der Startseite. Bei vielen Content Management Systemen heißen diese folgendermaßen:
- domain.de/index.html
- domain.de/home.htm
- domain.de/default.html
- domain.de/index.php
Problem dabei ist, dass sich die Startseite dann nicht nur über die eigentliche URL, sondern eben auch über die Startseiten-Dateiendung aufrufen lässt und somit Duplicate Content entsteht. SEO erfahrene Programmierer wissen dies und nutzen häufig das Canonical Tag dazu, auf die URL-Variante zu verweisen, welche auch wirklich im Index erscheinen soll.
Tipp
Die optimale Lösung für dieses Problem ist allerdings nicht das Nutzen des Canonicals, sondern eine 301-Weiterleitung. Denn das Canonical-Tag stellt immer noch nur eine Empfehlung an die Suchmaschine dar. 301-Weiterleitungen sind jedoch klare Befehle, denen Crawler folgen. So werden Missverständnisse vermieden.
URL Tipp- oder Technikfehler
Nicht selten kommt es auch vor, dass verschiedene URLs für die gleiche Seite aufgrund von Tipp- oder Technik-Fehlern erstellt werden. Ein typisches Beispiel ist hier domain.de/hallo/ und domain.de/hallo1/. Gut programmierte CMS erkennen solche Fehler und leiten die alte Fehler-URL automatisch auf die neue weiter. Nichtsdestotrotz kommt es auch dazu, dass die alte URL nicht weitergeleiten wird und den Statuscode 200 auswirft, das heißt ganz normal erreichbar ist. Auch hier kann das Canonical Tag eingesetzt werden, um auf die richtige Webseite zu verweisen, muss aber nicht.
Tipp
An dieser Stelle wird auch ein 301 Redirect empfohlen. Im Idealfall wird dieses automatisch über das CMS generiert. Eine zweite Option ist, das Duplikat mithilfe der Meta Robots auf “noindex” zu setzen.
Www- oder https-Varianten
Nach einer SSL-Zertifikat-Umstellung von http und https versäumen es Programmier viel zu oft, entsprechende Weiterleitungen vorzunehmen. Die Seite sollte nämlich stets nur über die neue https Variante abrufbar sein. Aber auch der erfolgreiche Abruf von einer Seite mit und ohne www. stellt ein übliches Duplicate Content Problem dar. Das heißt der Abruf von www.domain.de/hallo/ und domain.de/hallo/ sollte optimiert werden. Genauso bei https://www.domain.de/hallo/ und http://www.domain.de/hallo/. Auch hier ist ein Canonical Einsatz grundsätzlich möglich. Die nicht gewünschte Variante sollte optimalerweise auf die gewünschte verweisen.
Tipp
Auch hier lautet unsere SEO Empfehlung wieder: Das Tag vermeiden, wenn es geht. So ist die beste Lösung wieder der Einsatz einer 301 Weiterleitung. Ideal ist eine domain übergreifende Einstellung über .htaccess.
Trailing Slash
Trailing Slash bezeichnet den Slash am Ende einer URL. Webseitenbetreiber nutzen diesen im SEO unter anderem, um die Ladezeit zu verringern. Der Suchmaschine wird mit dem Slash am Ende vermittelt, dass es sich nicht um eine Datei handelt, sondern um ein ganzes Verzeichnis, das an dieser Stelle endet. Duplicate Content entsteht in diesem Fall, wenn eine URL ohne und mit Trailing Slash abrufbar ist, also beispielsweise bei domain.de/hallo und bei domain.de/hallo/. Auch Fehler in der Technik können dazu führen, dass URLs versehentlich mit mehreren Trailing Slashs aufrufbar sind. Wie in den bereits vorgestellten Fällen ist hier der Einsatz des Canonicals grundsätzlich möglich.
Tipp
Die 301-Weiterleitung stellt jedoch auch hier wieder die beste Lösung dar. So zeigt ihr den Crawlern direkt, welche URL wirklich wichtig ist. Wie bei Duplicate Content durch www- oder https-Varianten, empfiehlt sich eine globale Weiterleitung über die .htaccess-Datei einzurichten.
Case Sensitivity
Case Sensitivity beschreibt, ob eine Suchmaschine bei der Analyse einer URL Groß- und Kleinschreibung berücksichtigt. Die gängigsten Suchmaschinen wie Google und Bing sehen keine Unterschiede in URLs mit Groß- oder Kleinbuchstaben, daher stellt deren SEO Optimierung keine Priorität in der deutschen Online Marketing Branche dar. Prinzipiell ist die Vermeidung von Duplicate Content hinsichtlich Case Sensitivity aber über den Canonical Einsatz möglich.
Tipp
Wenn Case Sensitivity nicht über den Server konfigurierbar ist, empfiehlt sich der Einsatz des Canonical Tags.
Domain übergreifender Canonical
Manch ein Online Marketing Beauftragter fragt sich vielleicht, ob sich das Tag auch domain übergreifend einsetzen lässt: also zum Beispiel ein Verweis auf domain.de/hallo/ zu abc.de/hallo/. Der Canonical Einsatz ist an dieser Stelle grundsätzlich möglich, wir möchten diese Frage jedoch auch nicht mit einem pauschalen “Ja” beantworten.
Tipp
Hier stellt sich jedem SEO zunächst die Frage: Warum sollte man ein Canonical Tag domain-übergreifend nutzen? Denn, wenn einem beide Domains gehören, sollte Unique Content auf jeder der beiden Domains angestrebt werden. Bei duplikaten Inhalten sollten die, die man nicht im Index sehen möchte, mit den Metarobots auf “Noindex” gesetzt werden.
Fall 2: Canonical bei Paginierung mit prev/next
Ein oft diskutierter Fall ist auch der Einsatz des Canonical-Tags bei der Paginierung mit Prev/Next. Die Paginierung kommt häufig bei Magazinen oder Online Zeitungen vor, wenn Artikel zum Beispiel sehr lang sind und verhindert werden soll, dass Nutzer während des Lesens unendlich scrollen müssen. Paginierungen generieren sich aber auch automatisch in WordPress Blogs auf den Übersichts-Seiten zu den einzelnen Blogartikeln, Blogkategorien und Tags.
Ein Beispiel für das Markup für z.B. /page=3 ist folgendes:
<link rel="prev" href="/page=2/">
<link rel="next" href="/page=4/">Websites mit dem prev/next Attribut zeigen Crawlern, dass die einzelnen Seiten zusammengehören und nicht jede einzelne Seite von dem Verbund indexiert werden soll. Meistens stellt die erste Seite die Hauptseite dar, in Foren können es aber auch Unterseiten mit den relevantesten Antworten sein, welche Suchmaschinen als wichtigste Seite indexieren. Von Bedeutung ist, dass man Google mit diesem HTML Attribut zeigt, dass einzelne URLs zueinander gehören und beim Ranking nicht in Konkurrenz zueinander stehen sollen. So kann zum Beispiel Crawl-Budget gespart werden und man verhindert die Indexierung von Seiten, welche keine guten Inhalte aufweisen.
Tipp
Das rel=”next” und rel=”prev” Attribut ist als orthogonaler Begriff zu rel=”canonical” zu verstehen. Verwendet man prev/next, dann sollte man darauf achten, dass entweder kein Canonical Tag im Einsatz ist oder, dass der Canonical auf jeder Seite auf sich selbst verweist.
Sonderfall bei der Paginierung
Hier gilt es jedoch einen Sonderfall zu benennen: Die Canonical Paginierung ist bei einer “view-all-Seite”, wie sie zum Beispiel in Blogs häufig existiert, möglich. Dann muss der Canonical nicht auf sich selbst, sondern kann auf die Übersichts-Seite aller paginierten Seiten verweisen. Zum Beispiel kann “http://www.example.com/article?story=abc&page=2&sessionid=123” folgendes enthalten:
<link rel="canonical" href="http://www.example.com/article?story=abc&page=2"/>
<link rel="prev" href="http://www.example.com/article?story=abc&page=1&sessionid=123"/>
<link rel="next" href="http://www.ihremusterdomain.de/article?story=abc&page=3&sessionid=123"/>Die Empfehlung bei sonstigen paginierten Seiten, welche nicht im Index auftauchen sollen, lautet, diese auf Noindex zu setzen. Mehr Informationen dazu, findet ihr auch in der Hilfe zu der Google Search Console.
Fall 3: Canonicals in Online Shops
In häufig komplexen Online Shops kommen Webseitenbetreiber nicht umher, Sortierungs- und Filteroptionen für die Nutzer bereitzustellen. Denn nur so lassen sich die Artikel zielgerichtet vertreiben. Daher möchten wir euch die gängigsten Funktionen im Kontext des Canonical-Tags kurz aufzeigen.
Sortierung

Sortierfunktion bei aboutyou.de
Wer nutzt sie nicht, die Sortierfunktion, bei der man Produkte zum Beispiel nach Beliebtheit, Neuheit, niedrigster und höchster Preis sowie nach Angeboten sortieren kann. Dabei generieren sich meist zahlreiche Parameter URLs. Webmaster wollen aber häufig nicht, dass Google und Co. diese URLs einzeln crawlen. Meist ist nur die Hauptseite der jeweiligen Produktkategorie für den Index relevant.
Beispiel: onlineshop.de/produkte?zeigealles & onlineshop.de/produkte?nachguenstigempreis
Tipp
Grundsätzlich ist hier der Einsatz einer Canonical URL möglich. Die Empfehlung von uns lautet jedoch: Parameter-URLs, welche nicht im Index erscheinen sollen, am besten wieder mit der Metaangabe noindex aus dem Index ausschließen lassen.
Filter

Filterfunktion bei aboutyou.de
Eine weitere häufig in Online Shops genutzte Funktion ist das Filtern. Hier können Kaufinteressenten zum Beispiel nach Größe, Marke oder Material filtern.
Beispiel: onlineshop.de/pumps_rot & onlineshop.de/pumps_buffallo
Tipp
Auch im Fall des Shop-Filters könnt ihr das Tag grundsätzlich anwenden. Wir empfehlen jedoch auch an dieser Stelle darüber nachzudenken, ob ihr mit der Seite wirklich ranken wollt. Wenn nein, solltet ihr die Filter-URL direkt auf Noindex setzen. Wenn ja, empfehlen wir dringend einzigartige und keywordoptimierte Inhalte zu veröffentlichen, sodass ihr eine Chance habt für eure wichtigsten Begriffe zu ranken. Aber auch hier gibt es bereits intelligente Online-Lösungen wie das OSG Productfeed CMS, mit denen ihr Unique Content automatisiert erstellen könnt.
Canonical Tag ohne Duplicate Content
Braucht man das Canonical Tag auch ohne Duplicate Content? Ist man sich sicher, dass keine duplikaten Inhalte auf der eigenen Website ausgezeichnet werden müssen, könnte man doch darauf verzichten, oder nicht? Nein ganz so einfach ist es nicht. SEOs, darunter auch Google-Guru John Müller, empfehlen grundsätzlich das Canonical Tags auf sich selbst zu verweisen, sofern kein anderer Verwendungsbedarf vorliegt.
John Müller während eines Google Webmaster Hangouts sagte folgendes dazu:
“I recommend doing this self-referential canonical because it really makes it clear to us which page you want to have indexed, or what the URL should be when it is indexed.
Even if you have one page, sometimes there’s different variations of the URL that can pull that page up. For example, with parameters in the end, perhaps with upper lower case or www and non-www. All of these things can be cleaned up with a rel canonical tag.”
Das bedeutet im HTML Code jeder einzelnen Seite muss es ein Canonical Tag geben, das entweder auf sich selbst verweist oder in den oben vorgestellten Fällen auf die jeweilige Originalquelle. So könnt ihr euch vor möglichen zukünftigen Technik-Fehlern wappnen wie zum Beispiel vor internen und externen Verlinkungsfehlern.
Sie finden den Artikel interessant?
Jetzt zum Newsletter anmelden und kostenlos mit Neuigkeiten und Online Marketing Tipps versorgt werden:
Häufige Fehler
Wie viele andere Themen im technischen SEO sind Fehler bei Canonicals bei den meisten größeren Websites an der Tagesordnung. Die folgende Liste gibt euch einen Überblick zu einfach vermeidbaren Fehlern.
Der Einsatz ist empfehlenswert, wenn folgende Voraussetzungen erfüllt sind:
- URL verweist auf eine Seite mit dem Statuscode 200
- URL verweist NICHT auf eine URL mit dem Tag “noindex”
- URL verweist NICHT auf eine URL, welche mit der robots.txt gesperrt wurde
- URL verweist NICHT auf eine URL, die wiederum einen Canonical auf eine andere Seite setzt
- URL verweist NICHT auf eine URL, welche irgendwie gesperrt ist (z.B. durch einen Passwortschutz
Hilfreiche SEO Tools
Nun stellt ihr euch die Frage, wie ihr herausfindet, welche Canonicals bereits auf eurer Website existieren und wo Optimierungspotenzial besteht? Eine kostenlose Möglichkeit bietet Ihnen unser OSG Performance Suite. Hier könnt ihr euch per App als Free User registrieren und monatliche kostenfreie OnPage Crawls durchführen. Der Crawler zeigt auf, welche Fehler vorhanden sind. Außerdem erhaltet ihr auch den Fehlerverlauf und könnt euch so ein noch besseres Bild darüber machen, wann welche Fehler das erste mal auftraten und wann sie auch wieder behoben wurden.

Canonical Fehler im Onpage Crawler des OSG Performance Suites

Detailansicht der betroffenen URLs ohne Canonical Tag
Ein weiteres SEO Tool zur Prüfung des richtigen Canonical Einsatzes ist der Screaming Frog. Mithilfe dessen könnt ihr entweder alle intern verlinkten URLs in einer Excel Tabelle nach Canonical Filtern und diese prüfen. Möglich ist aber auch ein direkter Excel Export von Canonical-Fehlern, sodass man sich das manuelle Prüfen spart. Fehler müsst ihr hier jedoch eigenständig finden und bewerten, was im OSG Performance Suite der OSG automatisiert erfolgt. Diese kurze Anleitung gibt einen Einblick in das Nutzen des Screaming Frogs zur Identifikation von Canonical-Fehlern.

Schritt 1: Domain Crawlen, auf den Reiter “Directives” klicken und die Liste exportieren.

Schritt 2: Die Canonical Links exportieren bzw. kopieren und als Liste hochladen. Mode ändern von Spider auf List und die Liste hochladen oder einfach die Links reinkopieren. Jetzt werden alle Canonicals gecrawlt wie in Abschnitt 1.

Liste komplett exportieren mit allen Infos zu “noindex”-Status, Statuscode und vielem mehr
Die OSG Performance Suite
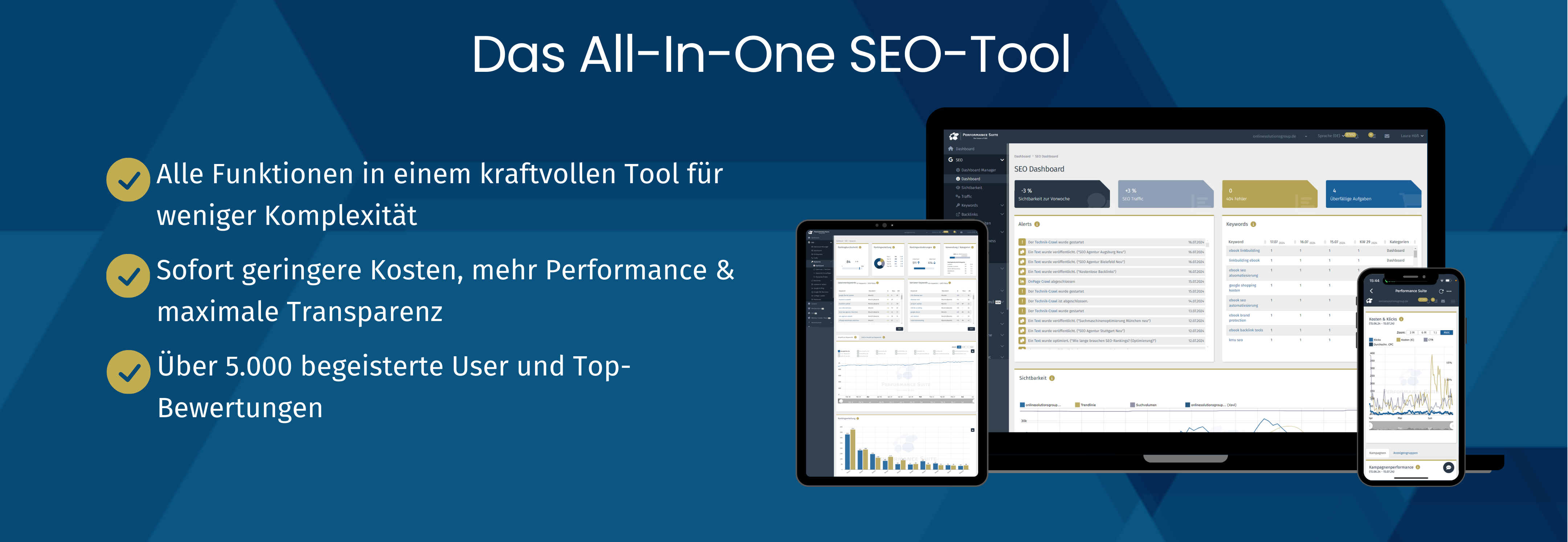
- Keyword-Tool, Content Suite, Backlink Suite, SEO Technik-Crawler, Local SEO
- Künstliche Intelligenz
- SEO Reporting
- SEA-Tool inkl. SEO-SEA-Synergien
- Brand Protection
- Pagespeed-Tool & Uptime Monitoring
- Schnittstellen zu Google Ads, Google Search Console, Bing u. a.
- Projektmanagement
- inkl. App und Push Notifications
- und viele weitere Features
Chancen & Risiken im SEO
Zusammenfassend lässt sich festhalten, dass es in der SEO Optimierung einige Chancen gibt, die mit der Verwendung des Tags zusammenhängen. Aber auch die Risiken sind nicht zu unterschätzen. Wie der Abschnitt “Häufige Fehler” zeigt, können simple fehlerhafte Einstellungen zu ernsten Konsequenzen führen.
Darüber hinaus sollten Anwender immer beachten: Das Tag gibt den Google Bots lediglich eine Empfehlung und keine direkte Anweisung. In den meisten Fällen von doppelten Inhalten ist es empfehlenswerter, das Tag auf “noindex” zu nutzen, selten auch die robots.txt in Betracht zu ziehen.
Was passiert aber, wenn bei doppelten bzw. ähnlichen Inhalten weder ein Canonical Tag gesetzt noch eine andere Maßnahme ergriffen wird? Ganz abgesehen von Abstrafungen wegen Duplicate Content wäre die Konsequenz, dass Google ähnliche oder identische Inhalte selbst bewertet. Google stuft diese dann entweder als gleichwertig ein oder priorisiert und indexiert gar eine Variante, die ihr selbst nicht favorisieren würdet.
Titelbild: ©Shutterstock/Roman023_photography





















Keine Kommentare vorhanden