Geliefert wie bestellt? Übersetzte Plagiate anstatt Unique Content

Copyright © Shutterstock / gerasimov_foto_174
Ohne Unique Content geht im SEO fast nichts mehr. Zur Praxis einer jeden guten SEO-Strategie gehört die Bereitstellung von qualitativ hochwertigem Unique Content. Sie garantieren Nutzern durch Unique Content in klug ausformulierten Ratgebern, Produktbeschreibungen oder News-Artikeln einen Mehrwert, der Leser idealerweise in Leads verwandelt und zu mehr Conversions führt.
Agenturen befinden sich seit der Content-Revolution in einer doppelt misslichen Lage. Potenzielle Kunden übernehmen die Online-Redaktion samt dazugehöriger SEO-Prozesse oftmals intern selbst, und selbst da, wo Agenturen Unique Content noch bereitstellen sollen, sind die Texte durch zu kleine Zeitkontingente wiederum auf externe Textanbieter wie content.de oder Textbroker angewiesen. Geschriebener Unique Content ist bei diesen Providern schon für nur wenige Cents pro Wort erhältlich. Das lohnt sich durchaus, birgt aber mittlerweile Risiken und Gefahren.
Unique Content billig und schnell
Genannte Anbieter von Unique Content werben dabei mit einer schnellen Verfügbarkeit und natürlichem Unique Content. In Zeiten von Tools wie CopyScape, die darauf spezialisiert sind, Duplicate Content zu erkennen, sollte das Entlarven von doppelten Inhalten auch kein Problem sein. Eigentlich. Denn durch die fortschreitende Verbesserung von Übersetzungstools wie den Google Translator oder deepl.com wird die Frage nach der Qualität auch von vermeintlichem Unique Content neu gestellt. Werden also Texte bei genannten Providern bestellt, heißt das noch lange nicht, dass sie Unique Content sind. Sie wurden womöglich einfach auf die Schnelle übersetzt. Hinweise auf übersetzte Plagiate liefern die Grenzen gängiger Übersetzungstools selbst, so ausgereift sie sich etwa auf deepl.com auch präsentieren. Probleme entstehen spätestens bei der Idiomatik oder bei englischsprachigen termini tecnici, also Spracheigentümlichkeiten oder bei Fachbegriffen, für die Übersetzungsprogramme gerne recht ulkige Lösungen parat haben. Lesen Sie also in bestellten Texten zu Software-Anwendungen etwas über einen “Werkzeugkasten” (für Tool Box) oder “Engines”, welche “eine bestimmte Webseite kratzen” lassen, so ist es mit Unique Content wohl nicht so weit her.
Übersetzungsplagiat 1: Ein bestellter Glossar-Artikel zum Thema Meta Tags.
In weiten Teilen als Plagiat erwies sich zum einen der georderte Unique-Content-Text zum Thema Meta Tags. Wie unsere Nachverfolgung ergab, setzt sich das Plagiat aus entsprechenden Fachartikeln aus Wikipedia und Moz zusammen. Dass offenkundige Fehler bzw. stilistische Entgleisungen wie im Abschnitt “[h2]Tipp: Wann auf eine Meta-Beschreibung verzichtet werden kann[/h2]” nicht gesehen wurden, lässt auch den fahrlässigen Umgang bzw. völlig fehlendes Qualitätsbewusstsein der Autorin erkennen: “… Obwohl die herkömmliche Logik besagt, dass es allgemein klüger ist, eine gute Meta-Beschreibung zu formulieren, als die Engines eine bestimmte Webseite kratzen zu lassen, ist dies nicht immer der Fall.” Inhaltlich erwies es sich, dass Struktur und Inhalte einfach zu einem Text zusammengefügt wurden, die plagiierten Passagen aus Moz sind grün, die Wikipedia-Abschnitte rot markiert:

Screenshot. Markierter Text Content.de
Rot markiert sind – wie erwähnt – die Wikipedia-Passagen zum Thema Metal-Element, welche übersetzt und übernommen wurden:

Screenshot: Wikipedia
Die grün markierten Textbereiche sind vom Online-Portal Moz übernommen und übersetzt. Pikant an der Sache: moz.com wird branchenweit rezipiert, weshalb ein Plagiat spätestens von bewanderten Marketern über kurz oder lang erkannt worden wäre:
Screenshot: Moz.com
Übersetzungsplagiat 2: Ein bestellter Glossar-Artikel zum Thema PageRank.
Wikipedia lieferte auch die Vorlage für den bestellten Artikel zum Thema PageRank. Wie ein genauer Blick ergab, waren es auch hier nicht nur einige Passagen, sondern ganze Abschnitte samt Struktur. Nur dreist kann es genannt werden, wenn die Texterin einfach Abschnitte plagiiert. Zum Beispiel:

Screenshot: Wikipedia
Plagiiert und übersetzt hat die Autorin hier:
[strong]Pagerank (PR)[/strong] ist ein Link-Analyse-Algorithmus, der jedem Element eines mit Hyperlinks verknüpften Satzes von Dokumenten, wie z. B. dem World Wide Web, eine numerische Gewichtung zuweist, um seine relative Bedeutung innerhalb des Satzes zu ermitteln. Der Algorithmus kann auf jede Sammlung von Entitäten mit wechselseitigen Zitaten und Referenzen angewendet werden. Das numerische Gewicht, das einem bestimmten Element [i]E[/i] zugewiesen wird, wird als Pagerank von [i]E[/i] bezeichnet und mit [i]PR (E)[/i] angegeben.
Auch in folgendem Absatz handelt es sich nicht um Unique Content, sondern es wurden Teile plagiiert:

Screenshot: Wikipedia
Im bestellten und gelieferten Text von content.de sah das dann so aus:
Ein [strong]Pagerank (PR)[/strong] ergibt sich aus einem aus der Mathematik kommenden Algorithmus, der auf dem Webgraphen basiert. Der Rangwert gibt die Wichtigkeit einer bestimmten Seite an. Ein Hyperlink zu einer Seite gilt sozusagen als Unterstützungsvotum. Der PR einer Seite wird rekursiv definiert und hängt von der Anzahl und PR-Metrik aller Seiten ab, die darauf verlinken (= eingehende Links). Eine Seite, auf die viele Seiten mit hohem PR verweisen, erhält selbst einen hohen Rang.
Auch der dritte Absatz des zweiten Abschnitts wurde phasenweise plagiiert:

Screenshot: Wikipedia
Seit [i]Page[/i] und [i]Brins[/i] Originalarbeit, wurden zahlreiche wissenschaftliche Arbeiten zu [strong]Pagerank (PR)[/strong] publiziert. In der Praxis kann das Konzept anfällig für Manipulationen sein. Ferner wurden Untersuchungen durchgeführt, um falsch beeinflusste PR-Rankings zu identifizieren. Ziel ist es, ein wirksames Mittel zu finden, um Links aus Dokumenten mit falsch beeinflusstem PR zu ignorieren.
Dass es sich nicht nur um einzelne Passagen, sondern fast die ganze Struktur des Textes handelt, beweist dieser Screenshot, links der bestellte Artikel, rechts das Übersetzungsplagiat aus Wikipedia (rot markiert):
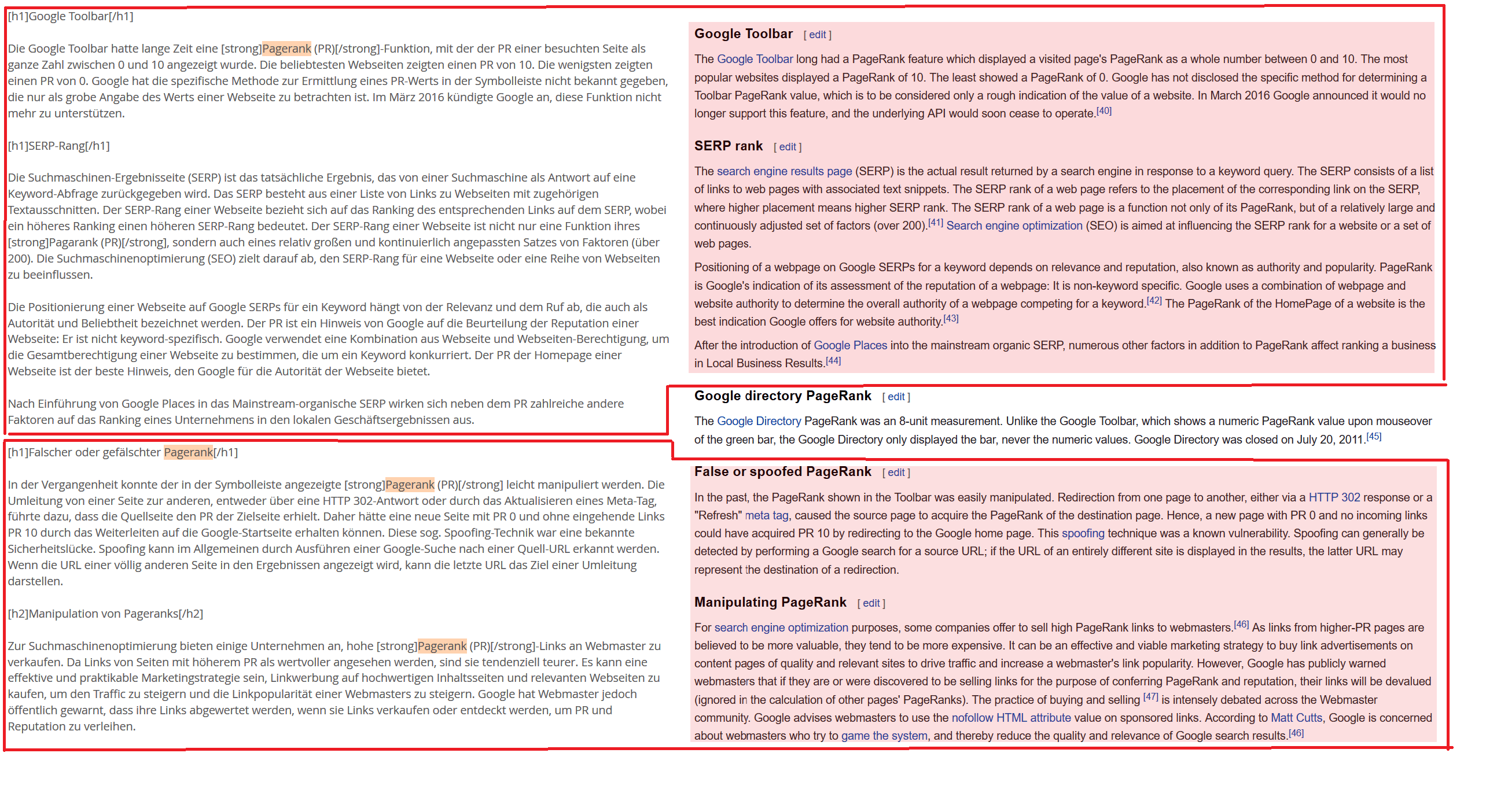
© Screenshot: Wikipedia & content.de
Tatsächlich haben Provider wie content.de auf diese Möglichkeiten Künstlicher Intelligenz bisher keine Antwort. Zwar findet sich bei content.de in der Eingabemaske für Texte ein entsprechendes Prüfprogramm (CopyScape) zur Identifizierung doppelter Inhalte und um damit Unique Content sicherzustellen; doch versagt die Technik dann, wenn es um übersetzte Inhalte aus dem Internet geht. Peinlich wird es spätestens, wenn es sich bei dem bestellten Content um übersetzte Plagiate weithin bekannter Verfasser ausgerechnet aus den Bereichen SEO und Online-Marketing handelt, welche branchenweit gelesen und zitiert werden.
Die Allgemeinen Geschäftsbedingungen (AGB) zumindest von content.de leisten hier weniger Erklärungshilfen, als Sie erwarten könnten. Formal entsteht mit der Textbestellung ein Vertragsverhältnis zwischen dem Schreiberling der Plattform und dem Auftraggeber (siehe AGB 4.2), was eben auch heißt: für etwaige Urheberrechtsverletzungen durch die bloße Übersetzung vorhandener Inhalte haftet dann eben nicht der Provider (siehe AGB 6.5), da die Beurteilung und die Verwertung des bestellten Textes in Händen des Textkäufers liege:
“6.5 Der Client verpflichtet sich, vor der Verwendung der erstellten Texte, diese inhaltlich und auf Rechteverletzungen zu prüfen (wie z. B. Markenrechtsverstöße, Wettbewerbsverstöße). Dabei ist insbesondere zu prüfen, ob der Text im geplanten Einsatzumfeld bedenkenlos verwendet werden kann. content.de übernimmt keine Gewähr dafür, dass der Text für einen bestimmten Zweck des Clients geeignet ist. Der Client trägt das Risiko der Verwendung ungeprüfter Texte. content.de übernimmt ausdrücklich keine Prüfung auf Rechtsverstöße und schließt jegliche Haftung diesbezüglich aus.”
In den AGBs findet sich auch der für content.de wichtige technische Kontrollrahmen definiert, der eben durch das Programm CopyScape für die Sicherstellung von Unique Content gesetzt wird. Faktisch können damit aber – wie dargelegt – auch Übersetzungs-Plagiate das Prüf-Programm problemlos unterlaufen.
Etwas anders sieht die Sache bei Textbroker aus: “6.2 Der Autor verpflichtet sich, nur sorgfältig eigenverfasste Texte einzureichen, an denen er alleine sämtliche Nutzungs- und Verwertungsrechte hält. Die Erstellung von Texten mittels Textgeneratoren oder automatischen Übersetzungstools ist nicht gestattet”, heißt es da in den AGB. Auf eine Anfrage der OSG hieß es zudem, dass die Textbeurteilung durch Textbroker nach gewissen Plausibilitäts-Merkmalen wie die Schreibgeschwindigkeit erfolge, auch bemühe sich die Qualitätssicherung im Vorfeld der Autorenakquise um eine genaue Kontrolle eingereichter Probetexte. Aber, so lautet das schlussendliche Fazit von Textbroker, eine hundertprozentige Sicherheit von Unique Content gebe es derzeit bei keinem Anbieter.
Unique Content als Frage der Technik
Viele dieser in Prüfprogramme und AGBs übersetzten Strategien gegen Duplicate Content erscheinen mit der Möglichkeit von schnellen Übersetzungs-Plagiaten in einem neuen Licht. Ähnlich wie andere Anbieter im E-Commerce auch sollten Provider wie content.de gezielt gegen Plagiate vorgehen; der Hinweis auf unausgereifte technische Lösungen hilft nicht weiter und geht vor allem an Kundenbedürfnissen vorbei. Anders als bei gefälschten Sneakern oder Smartphones kann der Schaden bei Urheberrechtsverletzungen schnell beträchtliche und durchaus existenzbedrohende Ausmaße erreichen!
Das Billighemd heutiger Content-Erstellung
Lohnt daher überhaupt ein Text-Einkauf? Auf Agenturseite, wo Zeit sprichwörtlich Geld ist, aber auch bei “Direktverwertern” in Betrieben und Unternehmen dürfte sich diese Frage nun umso dringlicher stellen. Wollen Sie hochwertigen Unique Content bestellen, bedarf es hierfür eines längeren Briefings; und ein gut formuliertes Briefing setzt eine ausgiebige inhaltliche (Keyword)Recherche voraus, um den Autor auch thematisch in die sprachlich und inhaltlich passende Richtung zu lotsen.
Der Texteinkauf hat vor allem preisliche Vorteile und stößt in der Praxis da auf Grenzen, wo es in die Tiefe gehen soll. Soll ein unverwechselbarer Brand samt konsistenter Markenidentität etabliert werden, sind eingekaufte Texte unter anderem aufgrund des Aspekts Unique Content sicher nicht der Königsweg. Problematisch ist dann die Realisierung eines professionellen Gesamtkonzepts:
- Text- & Bildsprache
- Tonalität
- Layout & Grafik
- Gliederung
- einheitliche Call-to-Actions
Neben diesen klassischen Wirkfeldern von Werbetextern kommt die technische Komponente hinzu, vom Tracking über unzählige Fein- und Nachjustierungen: das Korrektorat, oder die Verlinkungspraxis oder Prüfungen über gängige WDF-IDF-Tools. Spätestens mit unzähligen Übersetzungs- und Kontrollschleifen – prinzipiell geht es ja um alle relevanten europäischen Sprachen – dürfte sich dann aber bei vielen Unternehmen die Frage nach dem ökonomischen Sinn stellen. Agenturen dürften dann bei qualitativ hochwertigen Gesamtkonzepten immer noch die Nase vorn haben.
Blicken Sie von hier aus zurück, so können Sie festhalten, dass sich durch diese Praxis des billigen Texteinkaufs einmal mehr Prinzipien zu Tode rasen. Wo eine rücksichtslose Discountisierung und “Geiz ist geil!”-Mentalität überhandnehmen, braucht sich niemand über die Kollateralschäden zu wundern. Kreativität bemisst sich dann vor allem darin, Qualität den Bach heruntergehen zu lassen oder eben andere zu übervorteilen. Insofern ist gerade die Content-Revolution dabei, ihre eigenen Kinder zu fressen. Wo Mehrwert und Relevanz permanent im Mund geführt werden, aber chronisch nur auf den Preis geschaut wird, wird vor allem liebloser Schund produziert. Greifbar ist der Irrsinn schon längst auf unzähligen sozialen Netzwerken zur visuellen Selbstdarstellung. Wenn Bilder am laufenden Band hochgeladen werden, schwindet am Ende die Qualität. Das meiste, das gepostet wird, interessiert schlichtweg niemanden.
Die Rückkopplungseffekte eines wahnhaft kollabierenden Nützlichkeitsdenkens liegen aber jedem schon klar vor Augen, egal, ob bei Massentierhaltung, CO2-Ausstoß oder bei der Ausbeutung in der Textil-Industrie. So beschleichen einem Kunden von content.de die gleichen Empfindungen, die Sie beim Betreten von H&M oder McDonald’s verspüren: Der Discount etablierter Content-Erstellung eben. Die Praxis wird spätestens dann allen auf die Füße fallen, wenn der Google-Bot die Qualität von Texten tatsächlich evaluieren kann.
Unique Content für wirklichen Mehrwert
Eine Rückbesinnung auf ganzheitliche Konzeptionen ohne Texte von der Stange wäre dann angezeigt. Um tatsächlich eine stimmige Marken-Identität zu entwickeln, bedarf es eines stimmigen Konzepts mitsamt einer einheitlichen Tonalität. Leisten können dies vor allem Inhouse-Texter und versierte Autoren auf Agenturseite, welche mit SEO-Spezialisten und Designern Hand in Hand arbeiten. Über stimmig konzipierte Gesamt-Konzepte wird dann auch das eingelöst, was Unique Content verspricht, nämlich Mehrwert und Nutzen, den Kunden begeistert und damit zu Leads und Conversions führt.
Die Performance Suite der OSG als Lösung für Unique Content
Um wirklich sicherzugehen, dass Ihnen Unique Content vorliegt, sollten Sie Ihren vermeintlichen Unique Content von einer Software prüfen lassen. Hier bietet sich die Performance Suite der OSG an. Neben vielen anderen SEO-Funktionen wie Backlink-Suite oder Security-Checks enthält die Performance Suite in der Content-Suite zusätzlich einen Duplicate-Content-Check. Bis zu 20 Texte können Sie monatlich auf doppelte Inhalte prüfen. Der Check wird automatisch ausgelöst, sobald Sie Content fertigstellen. Sie werden informiert, falls die Performance Suite fündig wird:
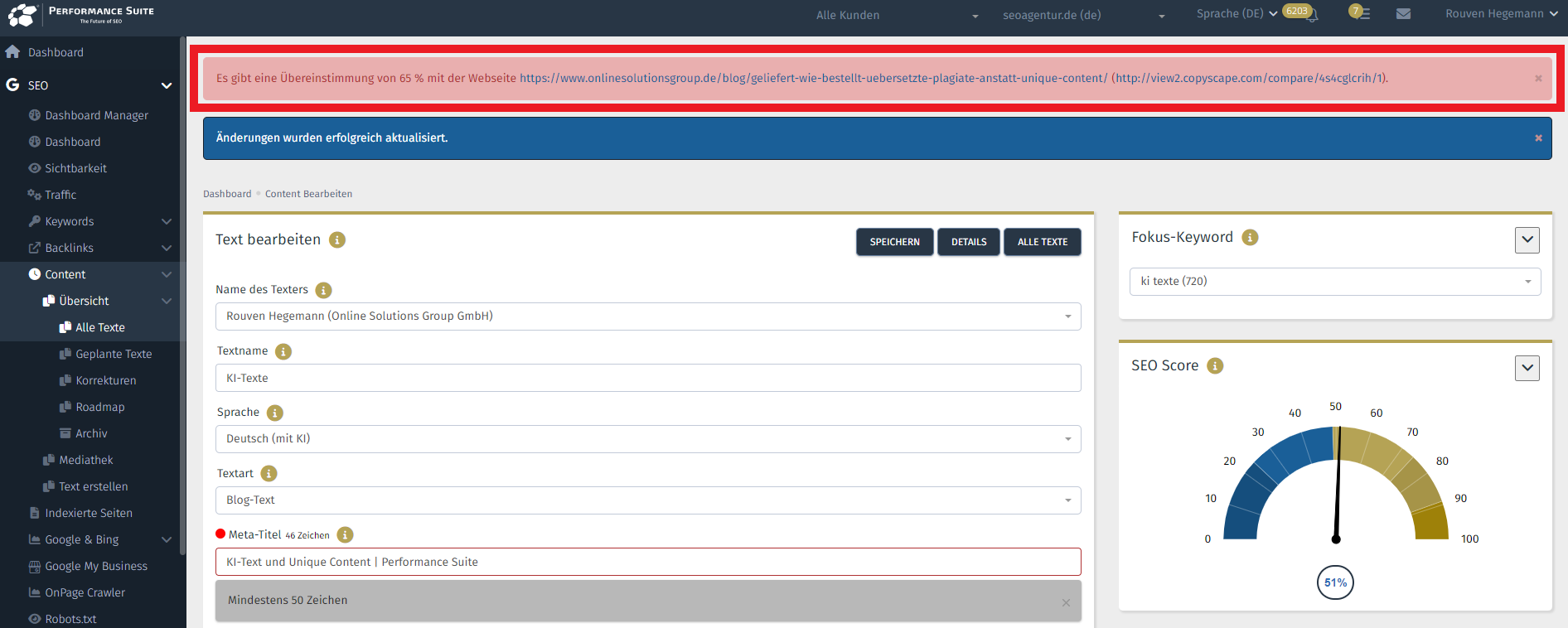
Copyright © OSG | Meldung über Duplicate Content in der Performance Suite
Sie erhalten weiter unten in der Content-Maske die Details zu den gefundenen Inhalten, inklusive Link zum Prüfen der Passagen:
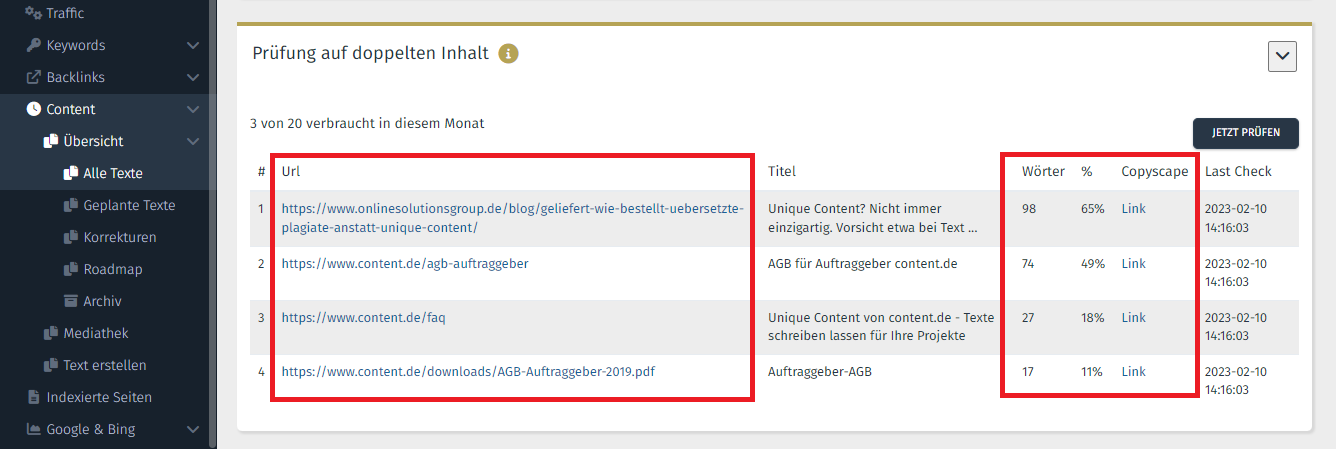
Copyright © OSG | Duplicate-Content-Prüfung in der Performance Suite
Link zum Nachweis von Duplicate Content via Copyscape: Die von uns überprüfte Passage wurde in einem Text gefunden und markiert.
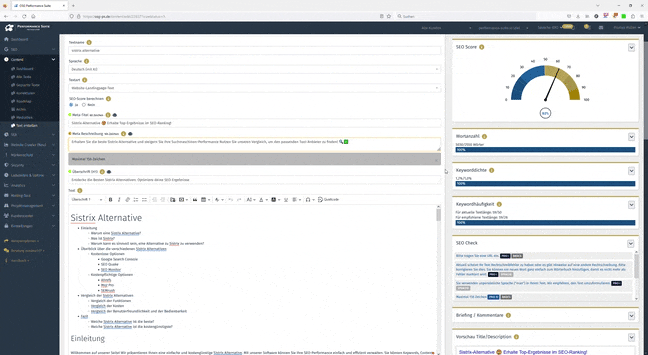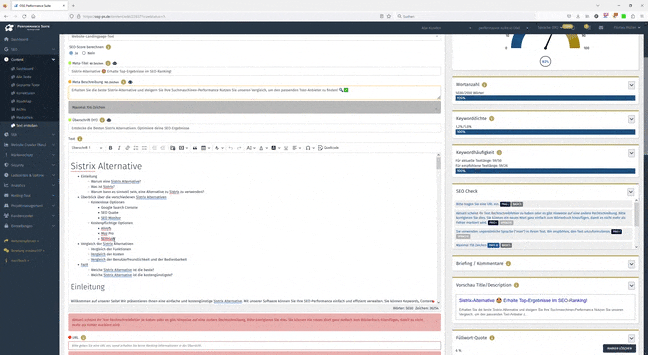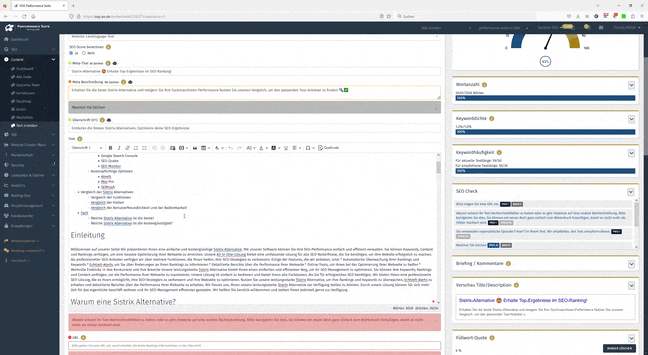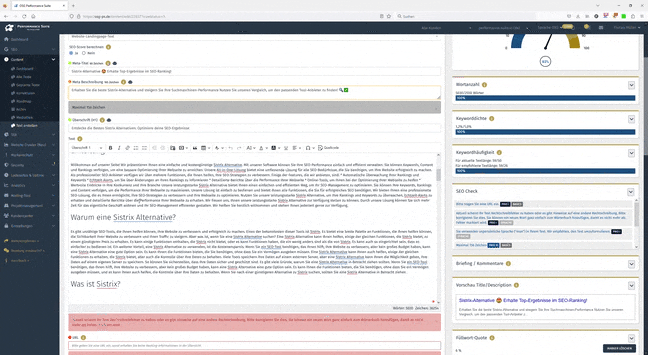
Mit der Content Suite können Sie durch die SEO-Empfehlungen ganz einfach sehr guten optimierten Content erstellen. Müssen Sie aufgrund der Budgetierung Texte von Textbrokern kaufen, können Sie diese Texte danach in die Content-Maske laden und ganz einfach nachoptimieren sowie die Textbroker-Texte auf Unique Content checken lassen.
Duplicate Content funktioniert auch andersherum: Prüfen Sie regelmäßig, ob Ihr Content gestohlen wird! Sie können und sollten Texte auch nachträglich auf Duplicate Content überprüfen, um unbefugte Plagiate ausfindig zu machen. Mit der Performance Suite ist das ganz einfach: Entweder klicken Sie im Text auf “Jetzt prüfen” oder wählen im Dashboard das Icon aus:
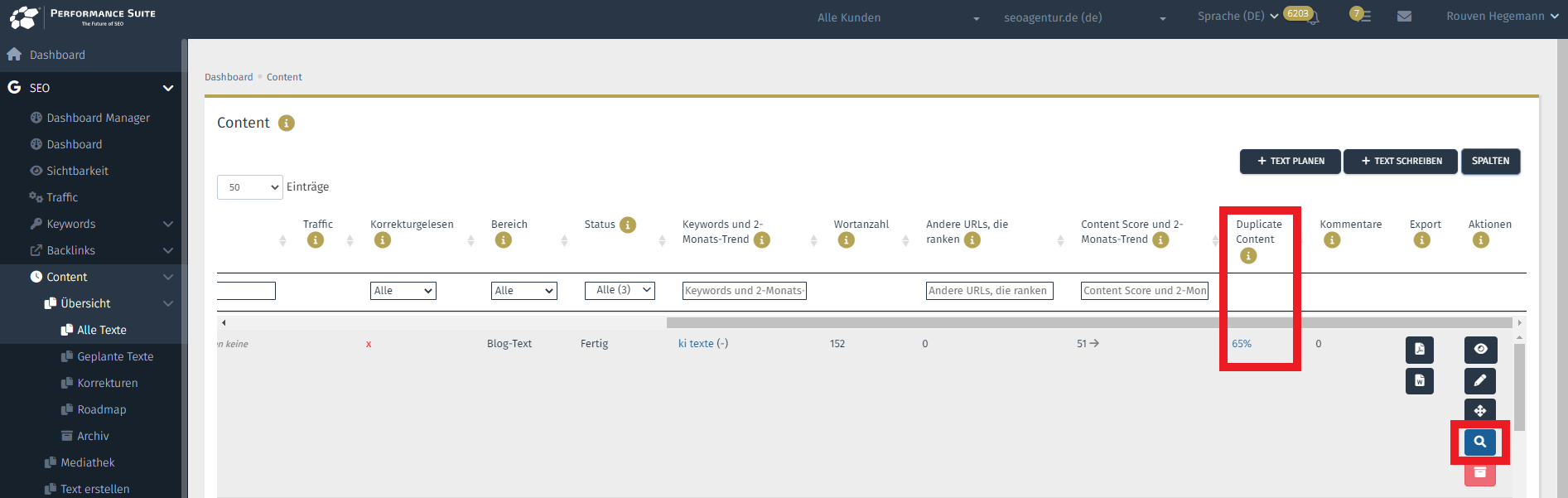
Copyright © OSG | Duplicate-Content-Check in der Content-Übersicht
Tipp: Wenn Sie herausfinden, dass Ihre Inhalte genutzt werden, ohne Sie als Quelle zu nennen, kontaktieren Sie den Website-Inhaber und fragen Sie nach einem Backlink! Machen Sie sich den DC-Check der Performance Suite zunutze, um Synergien mit Ihrem Linkbuilding zu schaffen.
Zum Content-ToolErfahren Sie in unserem kostenlosen e-Book, was weitere häufige Fehler im Content sind:
Zum e-Book
Die OSG Performance Suite
- Keyword-Tool, Content Suite, Backlink Suite, SEO Technik-Crawler, Local SEO
- Künstliche Intelligenz
- SEO Reporting
- SEA-Tool inkl. SEO-SEA-Synergien
- Brand Protection
- Pagespeed-Tool & Uptime Monitoring
- Schnittstellen zu Google Ads, Google Search Console, Bing u. a.
- Projektmanagement
- inkl. App und Push Notifications
- und viele weitere Features
Unique Content von Künstlicher Intelligenz: ChatGPT & Co.
Was hat es mit KI-Texten auf sich?
Immer populärer in der Content-Erstellung wird Künstliche Intelligenz. Durch ein kurzes Briefing des Auftraggebers erstellt die Künstliche Intelligenz basierend auf Algorithmen Unique Content. Es wird unter anderem berechnet, welches Wort auf ein Wort am wahrscheinlichsten folgen könnte. So entsteht nach und nach ein Text. Mit ChatGPT ist in der Content-Erstellung eine neue Zeit angebrochen. Mit bloßem Auge wird es sehr schwierig, KI-generierten Unique Content zu erkennen. Die Gefahr, die KI-generierter Unique Content birgt, ist, dass KI-Texte in sich grammatisch schlüssig wirken und nach außen hin den Eindruck von hoher Qualität vermitteln können. Allerdings weiß die KI inhaltlich nicht, was sie schreibt, was daher zu schlichtweg falschen Fakten bzw. realitätsfernen Passagen führen kann. Google findet KI-basierten Unique Content ergo nicht gut. Google kann wie andere Softwares noch nicht jeden Unique Content von KI erkennen, aber früher oder später wird es Wege geben, dies zu bewerkstelligen. Auch externe Texter von billigen Content-Plattformen greifen eventuell auf eine solche Art von Unique Content zurück. Hier ist Vorsicht geboten. Wichtig ist daher, KI-basierten Unique Content von menschlich geschriebenen unterscheiden zu können. Der Textbroker content.de sah sich mit einer derart großen Anfrageflut neuer Autoren konfrontiert, dass ein Aufnahmestopp verhängt wurde. So sollen Auftraggeber und “echte” Autoren vor unkontrolliertem KI-Spam geschützt werden.
Chancen und Risiken von ChatGPT & Co.
Bei KI-generiertem Content geht es nicht nur um Fragen der Rankings und Plagiate: Vor allem inhaltlich ist Vorsicht geboten! Denn Ihr Content soll von Menschen gelesen, als positiv bewertet und in irgendeiner Art befolgt werden. Sei es als Ratgeber oder Wissensquelle. Lassen Sie sich nicht täuschen: KI-Content hat Quantensprünge in der Linguistik geschafft. Unique Content von KI klingt immer “menschlicher” und kann Sätze logisch klingend verknüpfen. Allgemeinwissen und Fakten werden in vielen Fällen wahrheitsgemäß verarbeitet – allerdings nicht immer. Je sensibler ein Thema ist, desto weniger sollten Sie auf Unique Content der KI vertrauen. Und Sie sollten vermeintliche Zitate schon gar nicht ungeprüft übernehmen.
Urheberrechtsverletzungen spielen bei KI-Texten eine doppelte Rolle: Zum einen können Sie nicht wissen, ob Passagen mehr oder weniger komplett übernommen wurden und eventuell urheberrechtlich geschützt sind. Betreiben Sie mit Chat GPT SEO, können Sie das Programm direkt nach Zitaten und Quellen fragen – sehr praktisch! Aber Sie müssen diese Texte nichtsdestotrotz prüfen, denn wer sagt Ihnen, dass die von der KI genannten Zitate und Quellen korrekt sind?
Zum anderen stellt sich die Frage, wem die KI-Texte gehören. Wenn es also Unique Content mit realem Mehrwert ist und Sie ihn nutzen: Wem gehört er? Ist er geschützt? Ist es Ihr geistiges Eigentum, weil Sie die KI mit dem Briefing gefüttert und den Text als “gut zum Publizieren” bewertet haben?
Freilich bietet KI-genertierter Unique Content großartige Ideen fürs Brainstorming (bzw. übernimmt das Brainstorming für Sie). ChatGPT kann Ihnen beispielsweise Vorteile von E-Book-Readern gegenüber klassischen Büchern nennen, woran Sie gar nicht gedacht hätten – etwa viel mehr Platz im Regal. Aber wenn Ihnen empfohlen wird, E-Books zu nutzen, weil sie weniger Strom als Bücher verbrauchen, sollten Sie den Satz überdenken. Das gilt auch, wenn Sie komplexe Lösungen erwarten und sich mit dem Thema selbst nicht auskennen. Mit ChatGPT können Sie z. B. nach dem Fehler in einem Code fragen – sehr gut! Sie können den Vorschlag dann prüfen und als IT-Spezialist den Fehler nachvollziehen und beheben. Aber wenn Sie ohne Fachkenntnisse die Antwort der KI übernehmen, kann das schwere Konsequenzen haben.
Wenn Sie zu Chat GPT Google fragen, erhalten Sie verschiedene und eher defensive Antworten. Hieß es anfangs, dass alle automatisiert erstellten KI-Texte gegen Googles Richtlinien verstießen und abgestraft werden würden, rudert die Suchmaschine inzwischen zurück und betont, von Menschen geprüfter KI-Content sei in Ordnung. Aber woher weiß Google, ob ein Text von Menschen geprüft wurde? Da der Druck durch Microsoft und Bing stark steigt, hat auch Google die eigenen Anstrengungen bezüglich KI-Content intensiviert und ein Konkurrenzprodukt angekündigt. Im Grunde stehen für Google im Fokus, dass Content hilfreich und hochwertig sein muss. Umso wichtiger ist es für die Suchmaschine, Spam und Manipulationsversuche (z. B. durch Spam oder Propaganda) zu unterbinden. Inzwischen hat Google die eigenen Richtlinien zu KI-Content aktualisiert und “E-A-T” zu “E-E-A-T” erweitert: Experience, Expertise, Authoritativeness and trustworthiness.
KI-Texte von ChatGPT & Co. identifizieren
Obwohl es zunehmend schwieriger wird, KI-Texte zu identifizieren, gibt es verschiedene Software, die sich diesem Problem entgegenstellt. KI-Text-Erkennungssoftware arbeitet auch mit KI, die nach verschiedenen Mustern sucht, die auf einen KI-Text schließen lassen, jedoch für uns Menschen nicht erkennbar sind. Solch eine Software ist beispielsweise originality.ai. Neben Plagiaten erkennt die Software auch KI-generierten Unique Content.
Auch sind Formen “digitaler Wasserzeichen” möglich. Dabei kann es sich beispielsweise um eine bestimmte Wortwahl handeln, die für GPT typisch ist. Denkbar sind ebenfalls Vorschriften für Markierungen im Code oder bei der Verwendungen auf Websites – in etwa so, wie Sie “Anzeigen”/”Advertorials” markieren oder Links mit “No follow”/”Do follow” versehen.
Behalten Sie immer im Hinterkopf, dass Google selbst über einen komplexen Algorithmus verfügt und Milliarden in KI-Projekte investiert. Somit wird Google ganz sicher bereits viel weiter in der Identifikation von KI-genertierten Texten sein, als offiziell bestätigt wird.
Tipp
Sie können laut ChatGPT den User Agent OpenAI-GPT3 aussperren, damit OpenAI Informationen der eigenen Webseite nicht verwendet. So kann ChatGPT daraus keine eigenen Texte erstellen, welche dann von Dritten veröffentlicht werden könnten.
Fazit:
Inhalte bleiben relevant, guter Unique Content zudem sehr aufwändig. Doch bei der preislichen Abwärtsspirale, die mit Portalen wie Textbroker oder content.de in Gang gesetzt wird, braucht sich niemand über die Folgen zu wundern. Das Risiko der Abmahnung durch plagiierten Content ist nur eine Facette dieser Fehlentwicklung. Der Größenwahn allgegenwärtiger und schneller Verfügbarkeit von Inhalten führt dazu, dass sich das Konzept Content-Marketing selbst ad absurdum führt. Wir produzieren Inhalte, die kein Mensch liest, weil sie niemand braucht.
KI-generierter Unique Content wird zunehmend relevanter, allerdings bringt Unique Content einer KI die Gefahr von verfälschten Fakten und realitätsfernem Unique Content sowie eine Abstrafung von Google mit sich. Möglicherweise ist eine Lösung, bei ChatGPT Texte anzufordern, diese aber danach auf Logik/Inhalt und Grammatik zu prüfen und wenn erforderlich umzuschreiben.
Die mittelfristig optimale Lösung ist in den meisten Fällen sicherlich eine eigene Redaktion bzw. ein eigenes Marketing mit entsprechenden Content-Tools wie der Performance Suite: Damit können Sie selbst so viele hochwertige SEO-Texte erstellen, wie Sie möchten. Und Sie sehen anhand der automatischen Erfolgsprüfung, dass Google Ihre Arbeit belohnt!
FAQ – Häufig gestellte Fragen zu Unique Content
Was ist ein Unique Content?
Der Begriff Unique Content kommt aus dem Englischen und heißt so viel wie 'einzigartiger Inhalt'. Im Online-Marketing wird der Begriff 'Unique Content' verwendet, um Texte bzw. Website-Inhalte zu beschreiben, die es nur einmal im Internet gibt und somit einzigartig sind. Unique Content ist im Online-Marketing unerlässlich, um von Suchmaschinen nicht abgestraft zu werden.
Was ist content de?
Content.de ist eine Online-Plattform, auf der Texte günstig bestellt werden können. Freie Autoren erstellen die beauftragten Texte gegen Entgelt. Problematisch ist bei dieser Plattform, dass nicht ausgeschlossen werden kann, dass es sich um Duplicate Content handelt oder der Text von einer Künstlichen Intelligenz geschrieben wurde. Das könnte sich fatal auf Ihre SEO auswirken.
Was zählt als Duplicate Content?
Duplicate Content beschreibt identischen Content im Internet, der auf mehreren Seiten vorzufinden ist. Sind Texte auf Ihrer und auf einer anderen Webseite identisch, handelt es sich um externen Duplicate Content. Sind Texte Ihrer eigenen Unterseiten identisch, handelt es sich um internen Duplicate Content. Vermeiden Sie Duplicate Content. Nutzen Sie stattdessen Unique Content, da Google Seiten mit Duplicate Content oft abstraft.
Was zählt zu Content?
Im Online-Marketing wird unter dem Begriff sämtlicher Inhalt einer Webseite verstanden. Im klassischen Sinne ist das der Text bzw. der HTML-Text, aber dazu gehören auch Bilder, Graphiken und Co. Content ist im Online-Marketing unerlässlich für Ihre SEO, für das Nutzererlebnis und die Interaktion mit den Nutzern. Wichtig ist zudem, dass es sich um Unique Content handelt, um nicht abgestraft zu werden.




















Keine Kommentare vorhanden