Crawling

Copyright © Shutterstock / Willequet Manuel
Was ist Crawling?
Crawler sind Programme, die Webseiten auffinden und indexieren sollen. Andere Bezeichnungen dafür sind Webcrawler, Searchbot, Spider oder Robots. “Crawling”, also Kriechen, bezeichnet also die automatische Suche nach bestimmten Inhalten im World Wide Web, die damit verbundene Analyse sowie die anschließende Sortierung der gefundenen Daten. Natürlich können dabei auch E-Mail-Adressen gesammelt werden.
Der erste Webcrawler überhaupt war der World Wide Web Wanderer 1993. Dieser diente zur Messung des Wachstums des Internets. Heutzutage gibt es eine Vielzahl von unterschiedlichen Webcrawlern.
Welche Crawling-Arten gibt es?
Technischer Hintergrund
Der Webcrawler wandert über Hyperlinks von einer URL zur nächsten. Dabei speichert er alle gefundenen Adressen. Er reiht diese auf seiner Liste aneinander. Somit können alle verlinkten Webseiten gefunden werden. Danach werden die Seiten ausgewertet (Indexierung). Das ermöglicht es dem Webcrawler, später in den gesammelten Daten weitersuchen zu können.
Einsatzgebiete von Crawlern
Crawler können verschiedene Aufgaben haben und bei verschiedenen Gebiete Website-Betreibende unterstützen.
Für welche Einsatzgebiete sind Crawler zuständig?
- Crawler können eingesetzt werden, um einen Index zu erstellen. Man muss aber vorsichtig sein, da die Crawler eine limitierte Zeit bei der Website verbringen, deswegen sollte man die Seiten priorisieren. Sobald Websites indexiert werden, werden diese auch dem Nutzer angezeigt.
- Crawler können eingesetzt werden, um Website-Daten zu sammeln und auf dieser Basis dann Analysen durchzuführen. Informationen wie zum Beispiel an welche Tage und Uhrzeiten die Nutzer die Website benutzen können hier enthalten sein. Auch in der Performance Suite werden solche Daten angegeben, sowohl die Möglichkeiten einen Security-Check zu machen, um zu sichern, dass die Website sicher ist.
- Crawler können eingesetzt werden, um Daten aus einer Website zu extrahieren (z.B. mit XPath), um dann auch hier Analysen durchzuführen.
- Durch Data-Mining oder Data-Scrapping kann man E-Mail-Adressen oder Adressen von bestimmte Unternehmen sammeln.
Vor- und Nachteile
- Die Vorteile liegen eindeutig bei der Verwertung im Marketing. Bei der breit gefächerten Bandbreite an Informationen im Netz bleibt aber oft kein anderer Ausweg, als Daten zu filtern, analysieren und zu verwerten, um später auf diese zugreifen zu können. Marketing Strategien lassen sich so zielgerichteter ausrichten.
- Die Nachteile liegen vor allem bei der Server oder Hosting Last, die entstehen können.
Tipp
Häufig müssen etliche kostenintensive Tools herangezogen werden, um die Optimierungspotenziale im Rahmen einer OnPage-Analyse zu identifizieren. Unsere OSG Performance Suite enthält die kostenfreie und einfachere Lösung: der OnPage Crawler.
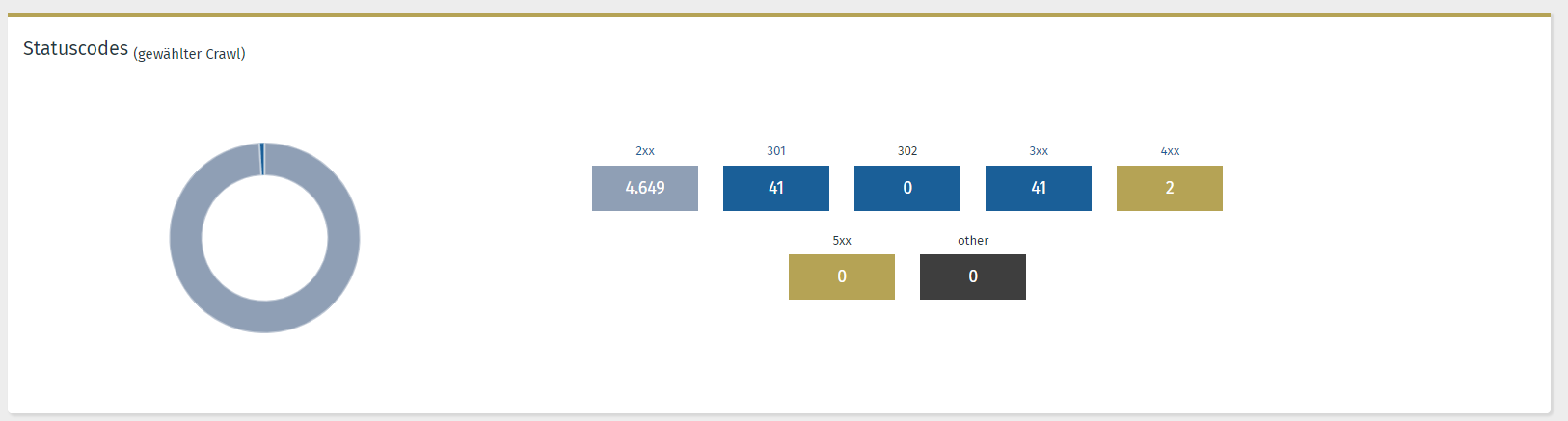
©OSG
Sie können sich auch gerne einen kostenlosen Account in unserer Performance Suite erstellen und von den Features profitieren!
Bekannte Crawler
Die bekanntesten Crawlern sind mit den Suchmaschinen streng verbunden, d.h. Suchmaschinen stellen Crawler zur Verfügung, die die Mission haben verschiedene Seiten zu prüfen und im Index zu ergänzen. Die bekanntesten Crawler lauten:
- Googlebot
- Bingbot
- Yandex Bot
- Baidu Spider
Bedeutung für SEO
Um indexiert zu werden und um in den Suchergebnissen vorzukommen, muss der Website-Betreibende das Crawlern einer Seite erlauben. Falls die Crawler geblockt werden, wird die Website in den organischen Suchergebnissen nicht angezeigt.
Ein regelmäßiges und automatisches Crawlen einer Website ist immer empfohlen, da es mehrmals Fehler entstehen und man somit diese so schnell wie möglich beheben kann. Mit der Performance Suite kann man einen regelmäßigen Check vom OnPage Crawler machen und Auffälligkeiten sofort beheben.
Fazit
Crawler sind ein wichtiger Technikpunkt, der konstant geprüft werden soll und bei Auffälligkeiten sollten diese auch schnellstmöglich korrigiert werden. Wenn der Crawler viele Fehler entdeckt, wird seine Aufgabe abgebrochen und die Website leidet an Sichtbarkeit und Traffic. Man sollte deswegen aufmerksam sein und alles unter Kontrolle haben, zum Beispiel durch die Performance Suite, die mehrere Alerts schickt, wenn Fehler entdeckt werden.
FAQ
Was bedeutet Deep Web und Cloaking?
Da viele Inhalte des World Wide Webs nicht über einfache Links, sondern Suchmasken oder Portale mit Zugangsbeschränkung erreichbar sind, haben Webcrawler in diesen Fällen das Nachsehen. Diese Bereiche werden daher Deep Web genannt. Darüber hinaus stellen ständige Veränderungen sowie Manipulationen der Inhalte ein Riesenproblem dar (Cloaking).
Wie kann Crawling verhindert werden?
Robots Exclusion Standards kann in der Datei robots.txt sowie in speziellen Meta-Tags im HTML-Header dem Webcrawler falsche Anweisungen zur Indexierung geben. Eine Tarpit ist eine Webseite, die dem Crawler mit falschen Informationen füttert, u. a. auch, um ihn auszubremsen.
Warum ist Web Crawling so wichtig?
Aus SEO Sicht sind die Crawlers wichtig, damit die Website indexiert wird und in den organischen Suchergebnissen vorkommt.
Was sind Web Crawler Bots?
Die Crawler indexieren alle Inhalte im Internet. Die Crawler müssen die Inhalte von fast allen Seiten im Internet kennen, damit diese den Nutzer richtige Informationen bei den Suchanfragen anbieten können.
Ist es rechtlich erlaubt, fremde Websites zu crawlen?
Beim Website Crawlern kann man eigentlich alle Websites crawlen, es wird als Web Scraping benannt. Das Scraping ist nur illegal, wenn man Urheberrechte oder die Befehle von der Website für Crawler, nicht berücksichtigt.
Sie haben noch Fragen?




















